S3 APIs integrations
S3 is a cloud-based object storage service designed to store and retrieve any amount of data.
Instance and workspace object storage are different from using S3 resources within scripts, flows, and apps, which is free and unlimited. This is what is described in this page.
At the workspace level, what is exclusive to the Enterprise version is using the integration of Windmill with S3 that is a major convenience layer to enable users to read and write from S3 without having to have access to the credentials.
Additionally, for instance integration, the Enterprise version offers advanced features such as large-scale log management and distributed dependency caching.
Windmill provides a unique resource type for any API following the typical S3 schema.
Add a S3 resource
Here are the required details:
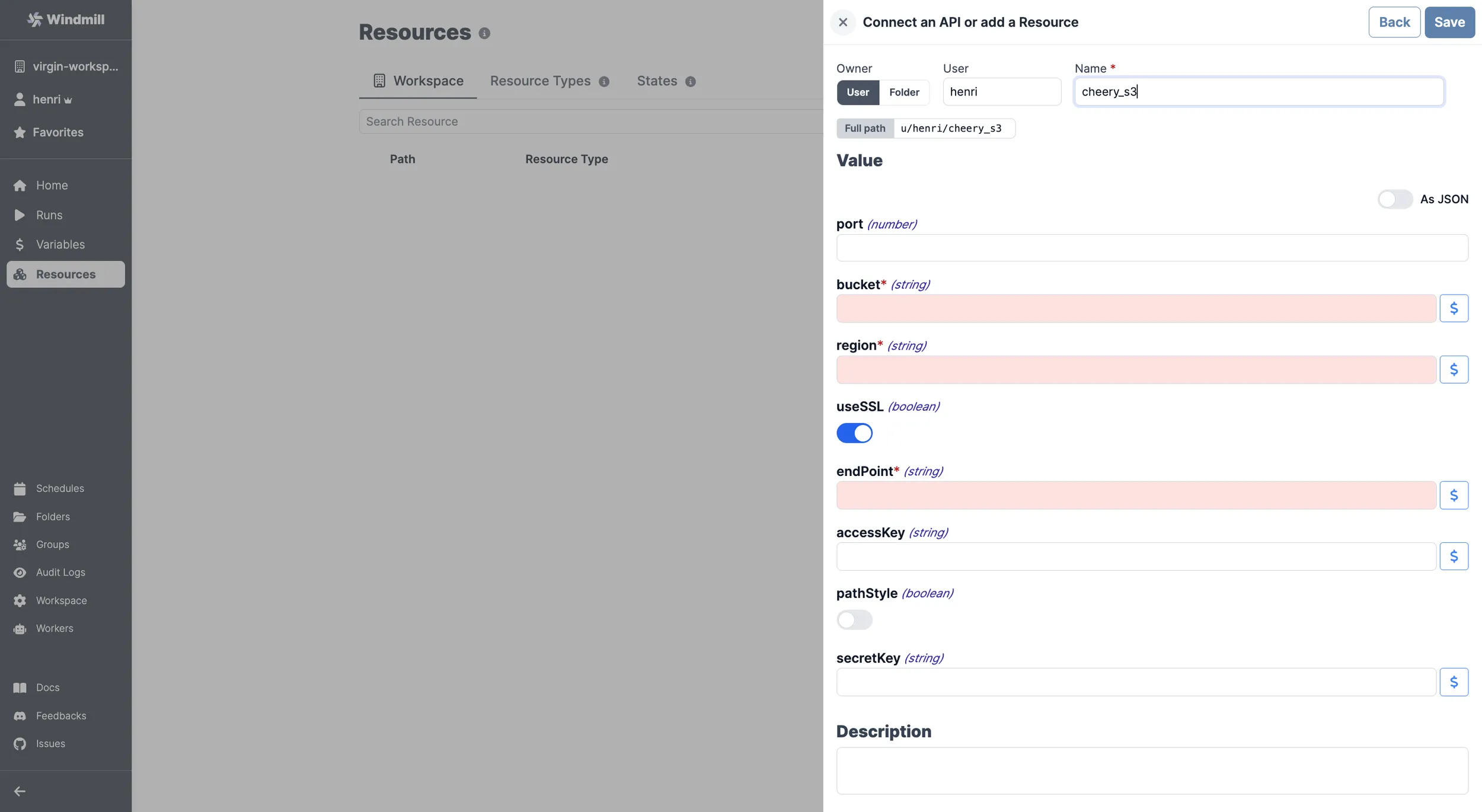
| Property | Type | Description | Default | Required |
|---|---|---|---|---|
| bucket | string | S3 bucket name | true | |
| region | string | S3 region for the bucket (e.g. eu-west-3) | true | |
| endPoint | string | S3 endpoint (e.g. s3.eu-west-3.amazonaws.com) | true | |
| useSSL | boolean | Use SSL for connections | true | false |
| pathStyle | boolean | Use path-style addressing | false | false |
| accessKey | string | Access key ID | false | |
| secretKey | string | Secret access key | false |
accessKey and secretKey are optional in the resource type but required by most providers (Amazon S3, Cloudflare R2, Tigris); leave them empty only for setups relying on public buckets or ambient credentials.
For guidelines on where to find these details on a given platform, see the provider pages:
Your resource can be passed as a parameter or fetched directly within scripts, flows, low-code apps and full-code apps.
Workspace object storage
Once you've created an S3, Azure Blob, or Google Cloud Storage resource in Windmill, you can use Windmill's native integration with S3, Azure Blob, or GCS, making it the recommended storage for large objects like files and binary data.

The workspace object storage is exclusive to the Enterprise edition. It is meant to be a major convenience layer to enable users to read and write from S3 without having to have access to the credentials.
Instance object storage
Under Enterprise Edition, instance object storage offers advanced features to enhance performance and scalability at the instance level. This integration is separate from the Workspace object storage and provides solutions for large-scale log management and distributed dependency caching.
