Handling files and binary data
In Windmill, JSON is the primary data format used for representing information. Binary data, such as files, are not easy to handle. Windmill provides two options.
- Have a dedicated storage for binary data: S3, Azure Blob, or Google Cloud Storage. Windmill has a first class integration with S3 buckets, Azure Blob containers, or Google Cloud Storage buckets.
- If the above is not an option, there's always the possibility to store the binary as base64 encoded string.
Workspace object storage
The recommended way to store binary data is to upload it to S3, Azure Blob Storage, or Google Cloud Storage leveraging Windmill's workspace object storage.
Instance and workspace object storage are different from using S3 resources within scripts, flows, and apps, which is free and unlimited. What is exclusive to the Enterprise version is using the integration of Windmill with S3 that is a major convenience layer to enable users to read and write from S3 without having to have access to the credentials.
Windmill's integration with S3, Azure Blob Storage, and Google Cloud Storage works exactly the same and the features described below work in all cases. The only difference is that you need to select an azure_blob resource for Azure Blob or a gcloud_storage resource for Google Cloud Storage when setting up the storage in the Workspace settings.
By setting a S3 resource for the workspace, you can have an easy access to your bucket from the script editor. It becomes easy to consume S3 files as input, and write back to S3 anywhere in a script.
S3 files in Windmill are just pointers to the S3 object using its key. As such, they are represented by a simple JSON:
{
"s3": "path/to/file"
}
When a script accepts a S3 file as input, it can be directly uploaded or chosen from the bucket explorer.
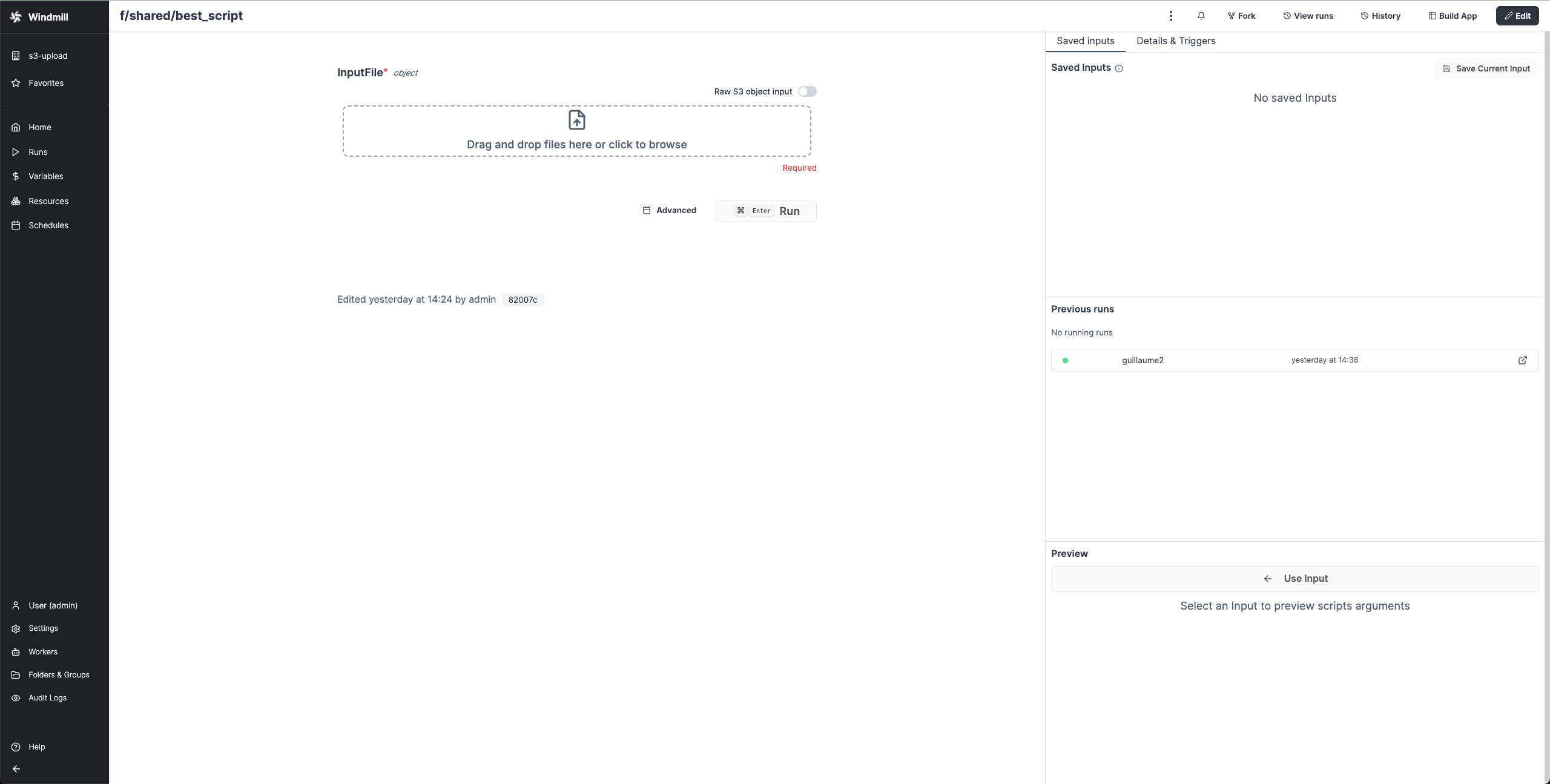
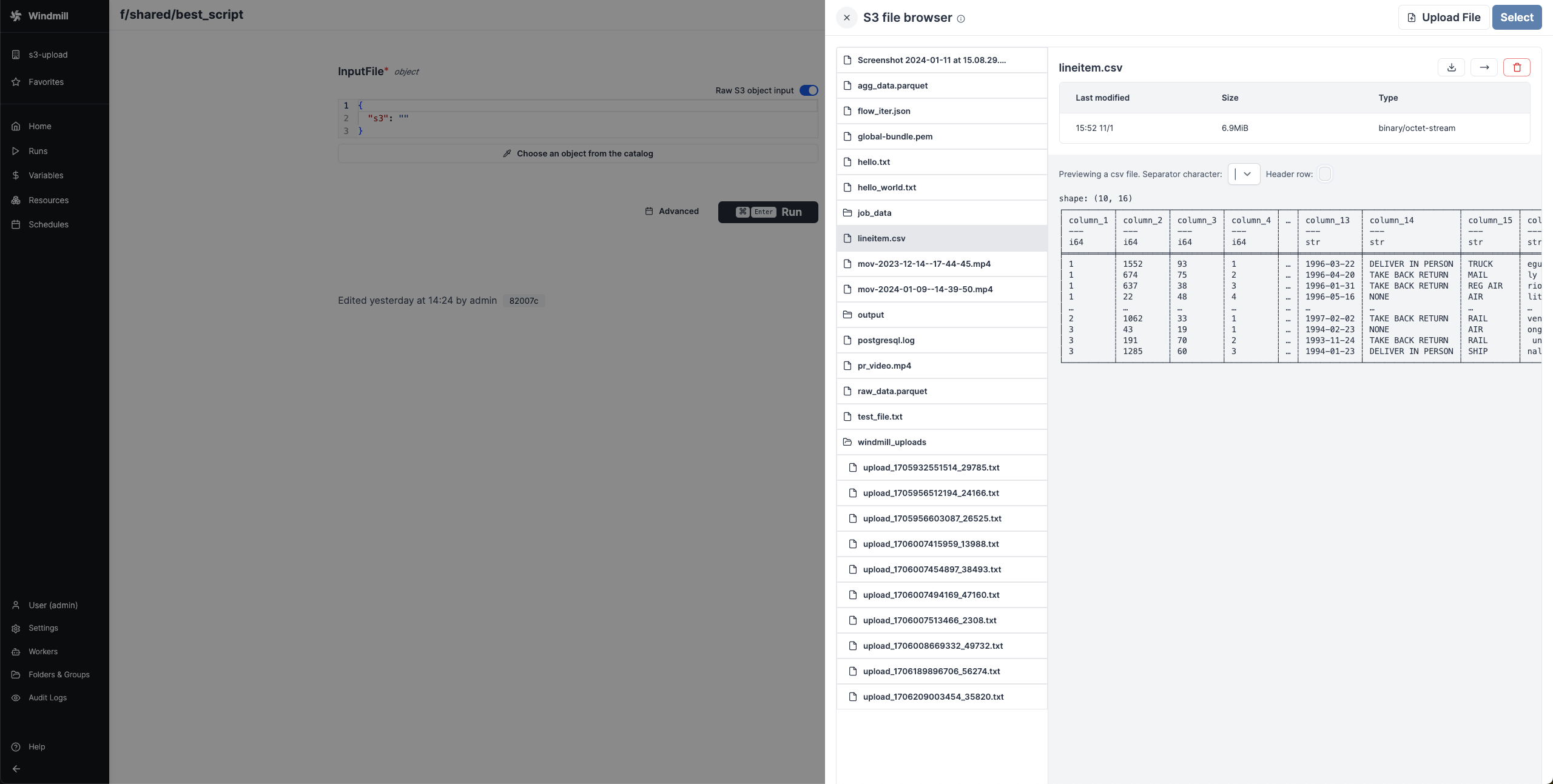
When a script outputs a S3 file, it can be downloaded or previewed directly in Windmill's UI (for displayable files like text files, CSVs or parquet files).
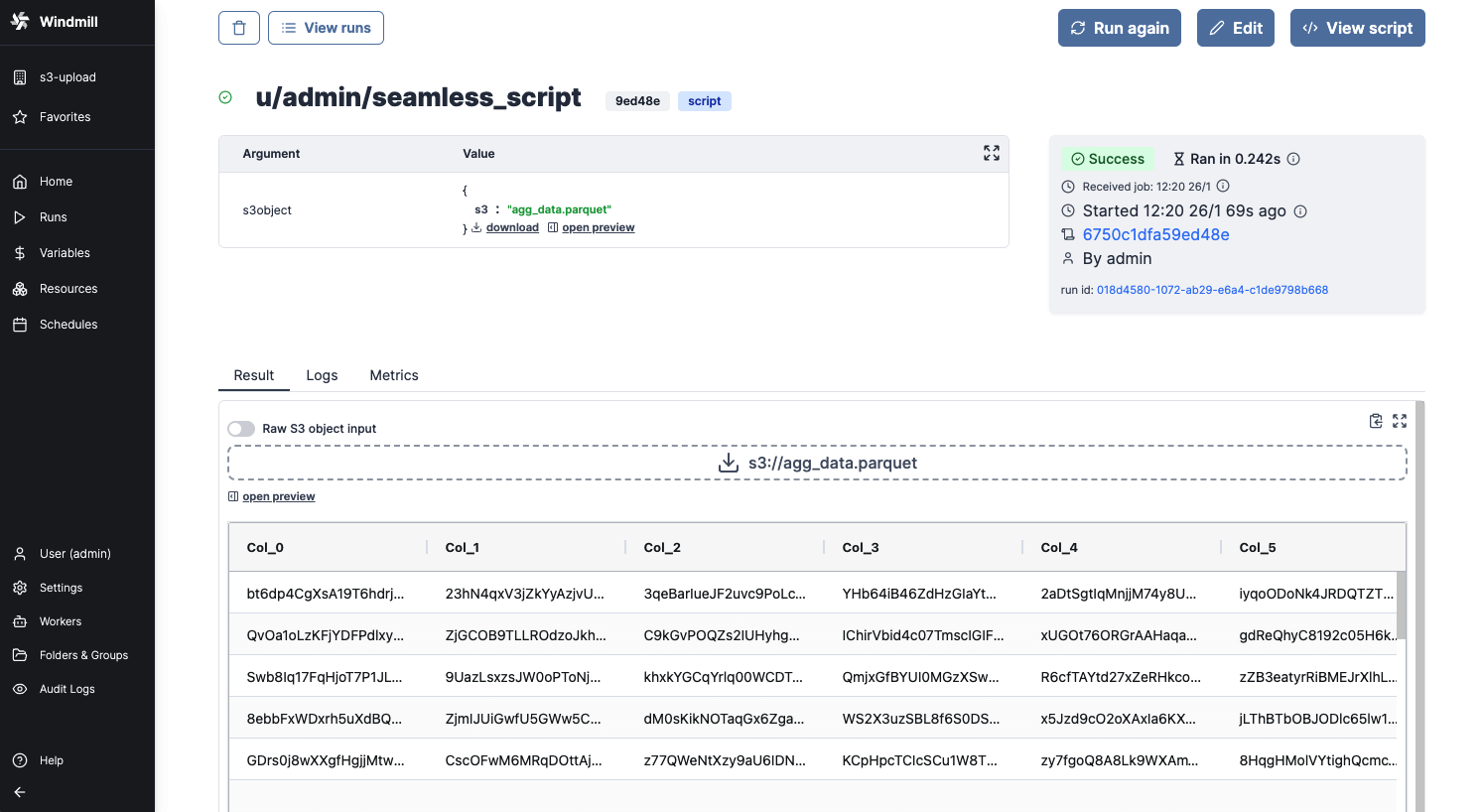
Windmill provides helpers in its SDKs to consume and produce S3 file seamlessly.
All details on Workspace object storage, and how to read and write files to S3 as well as Windmill embedded integration with Polars and DuckDB for data pipelines, can be found in the Object storage in Windmill page.
Base64 encoded strings
Base64 strings can also be used, but the main difficulty is that those Base64 strings can not be distinguished from normal strings.
Hence, the interpretation of those Base64 encoded strings is either done depending on the context,
or by pre-fixing those strings with the <data specifier:>.
In explicit contexts, when the JSON schema specifies that a property represents Base64-encoded data:
foo:
type: string
format: base64
If necessary, Windmill automatically converts it to the corresponding binary type in the corresponding
language as defined in the schema.
In Python, it will be converted to the bytes type (for example def main (input_file: bytes):). In TypeScript, they are simply represented as strings.
In ambiguous situations (file ino) where the context does not provide clear indications,
it is necessary to precede the binary data with the data:base64 encoding declaration.
In the app editor, in some cases when there is no ambiguity, the data prefix is optional.
Base64 encoded strings are used in:
- File input component in the app editor: files uploaded are converted and returned as a Base64 encoded string.
- Download button: the source to be downloaded must be in Base64 format.
- File inputs to run scripts must be typed into the JSON
string, encodingFormat: base64(python:bytes, Deno:wmill.Base64).