Build production-grade data pipelines
The DuckDB and Ducklake native orchestrator. Asset-based pipelines with managed materialization, partitions, data tests, column lineage and time travel. No Airflow, no Spark cluster, no warehouse bill.







Trusted by 4,000+ organizations, including 300+ EE customers at scale:

















Asset-based pipelines on DuckDB and Ducklake
Describe assets and their lineage instead of wiring tasks by hand, in the spirit of dbt and Dagster, with one difference: Windmill also runs the transforms (DuckDB), owns the storage and versioning (Ducklake), and schedules and triggers everything on your own workers. From ingestion (EL) to serving, in one platform. How it compares to dbt and Dagster.
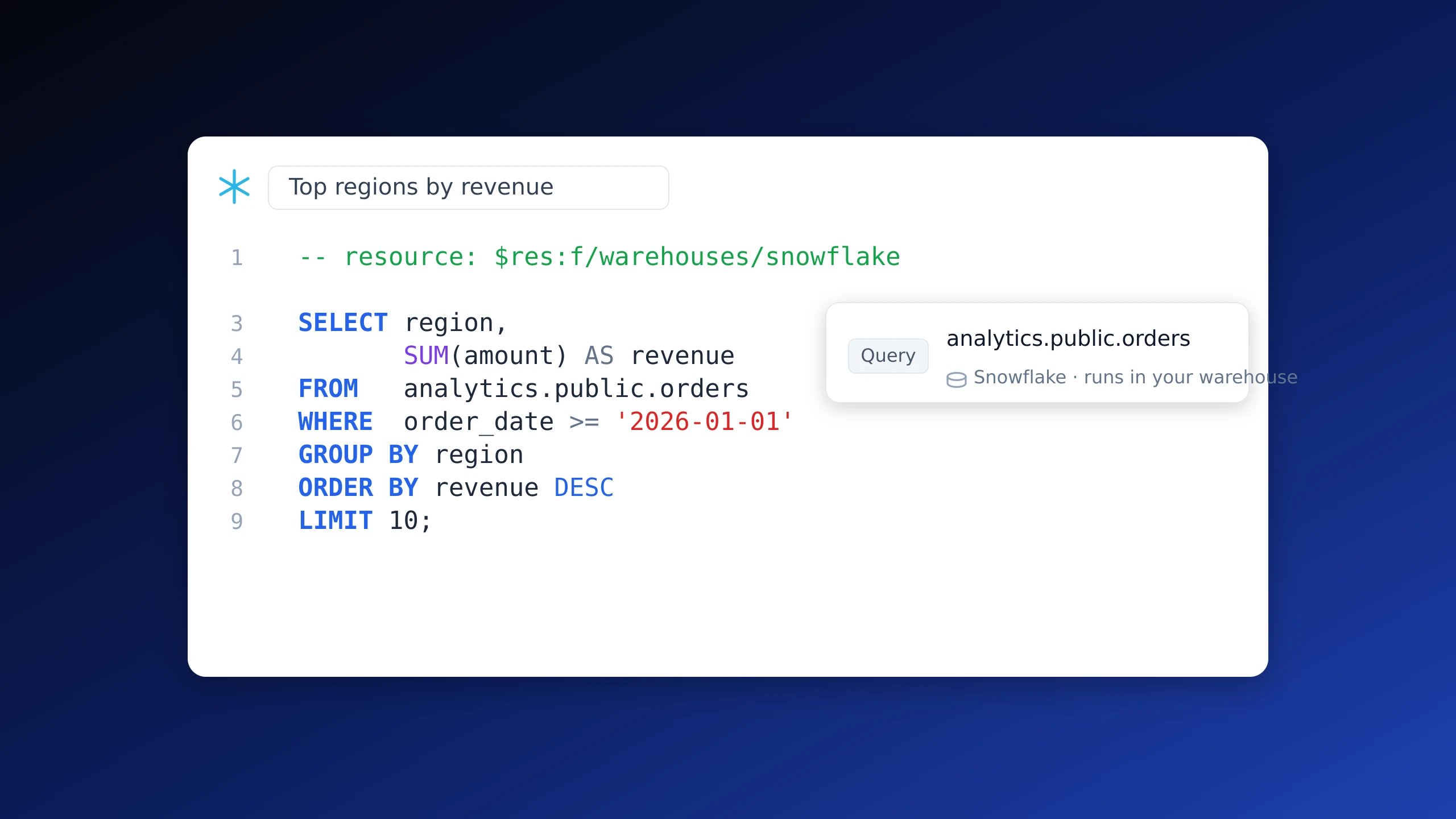
Pipelines from your code
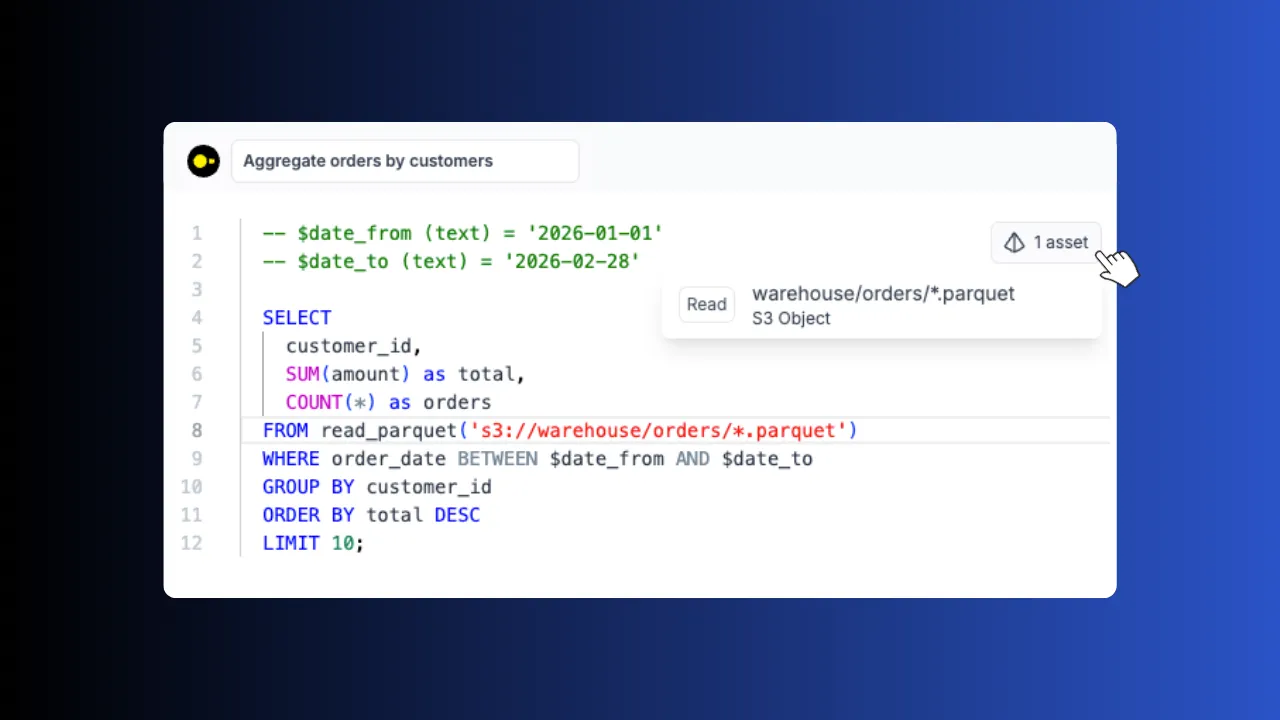
Add a few comment annotations (-- pipeline, -- on, -- materialize) and Windmill infers the execution graph from asset lineage: when a script writes a dataset, every script that reads it runs automatically. Schedules, webhooks, Kafka and Postgres CDC triggers plug into the same graph, so event-driven and batch live in one DAG.
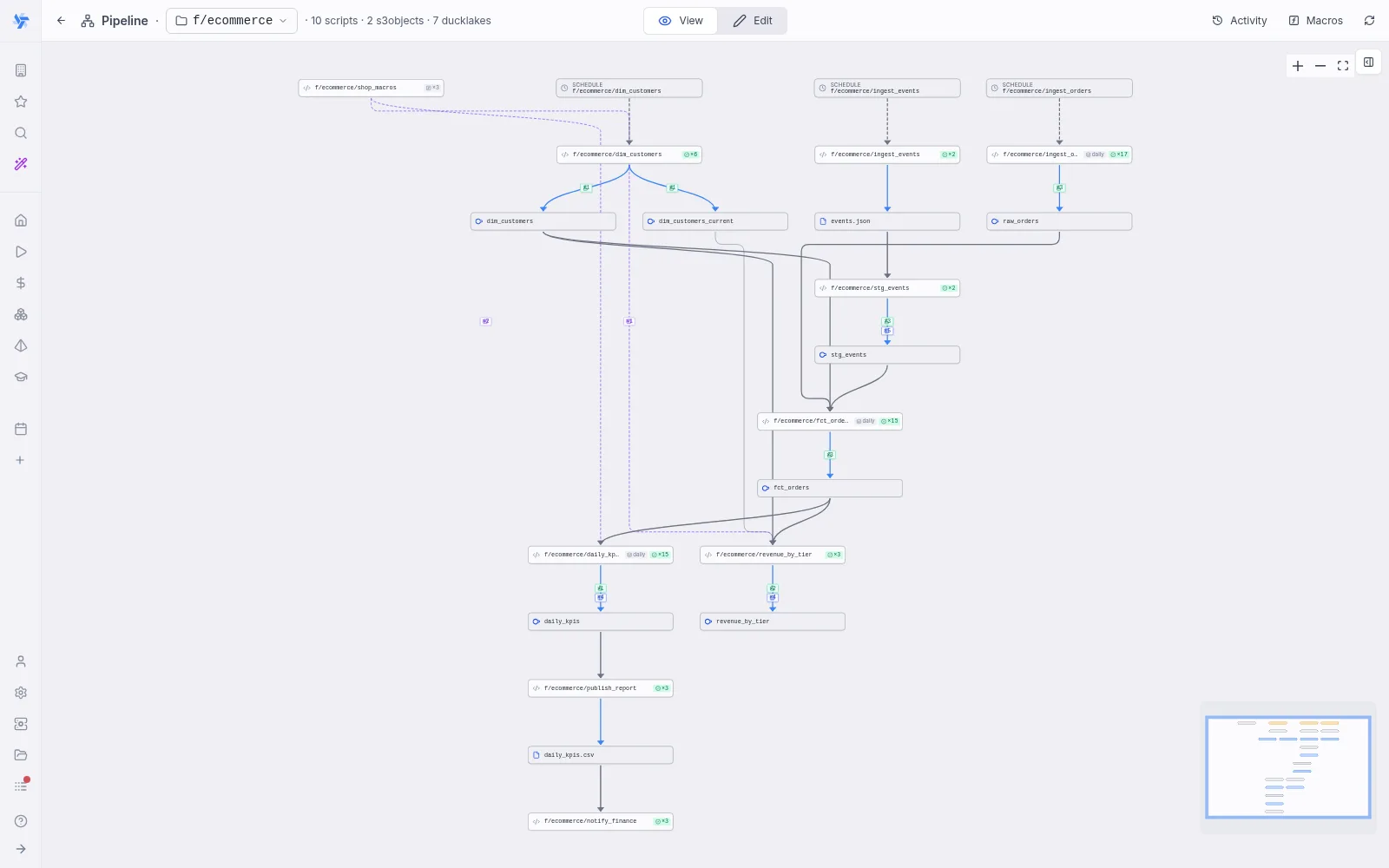
Managed materialization & SCD2
Write the DuckDB query for one slice; Windmill owns the write into a managed Ducklake table: replace, merge by key or append, always idempotent and snapshotted, so re-runs, retries and backfills are safe by construction. Add history to turn a keyed merge into a managed SCD2 dimension with as-of joins.
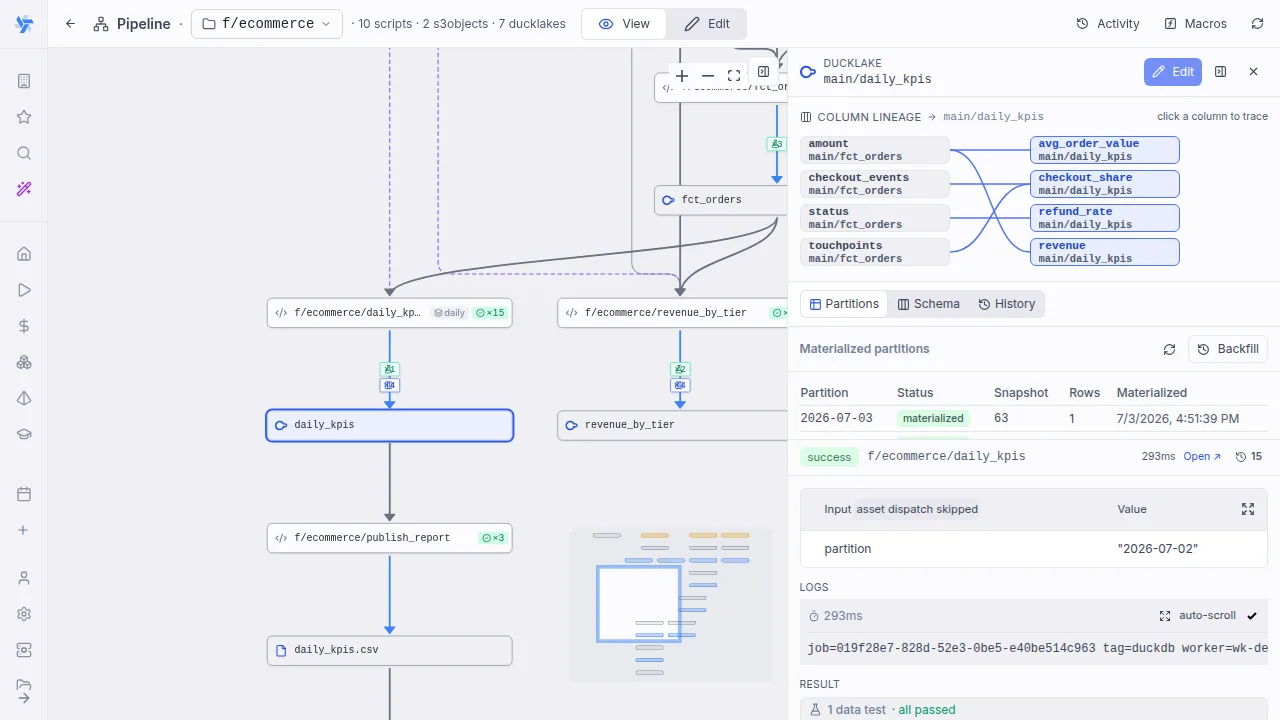
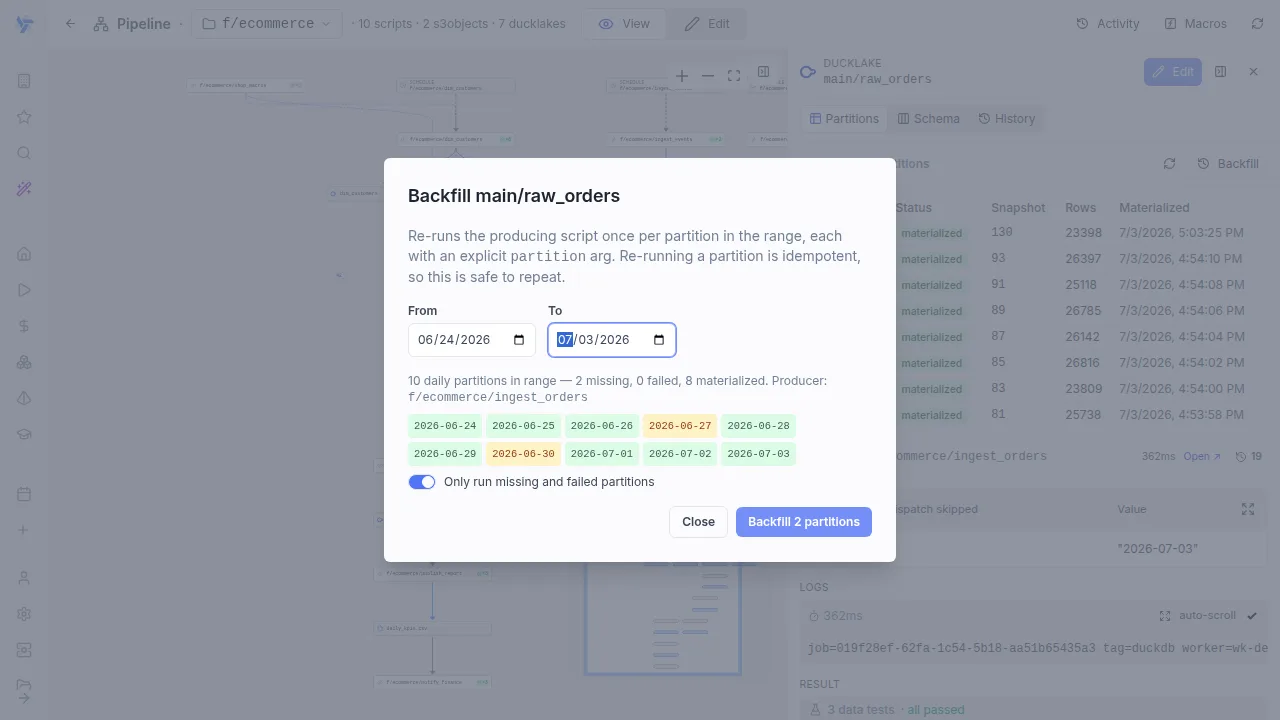
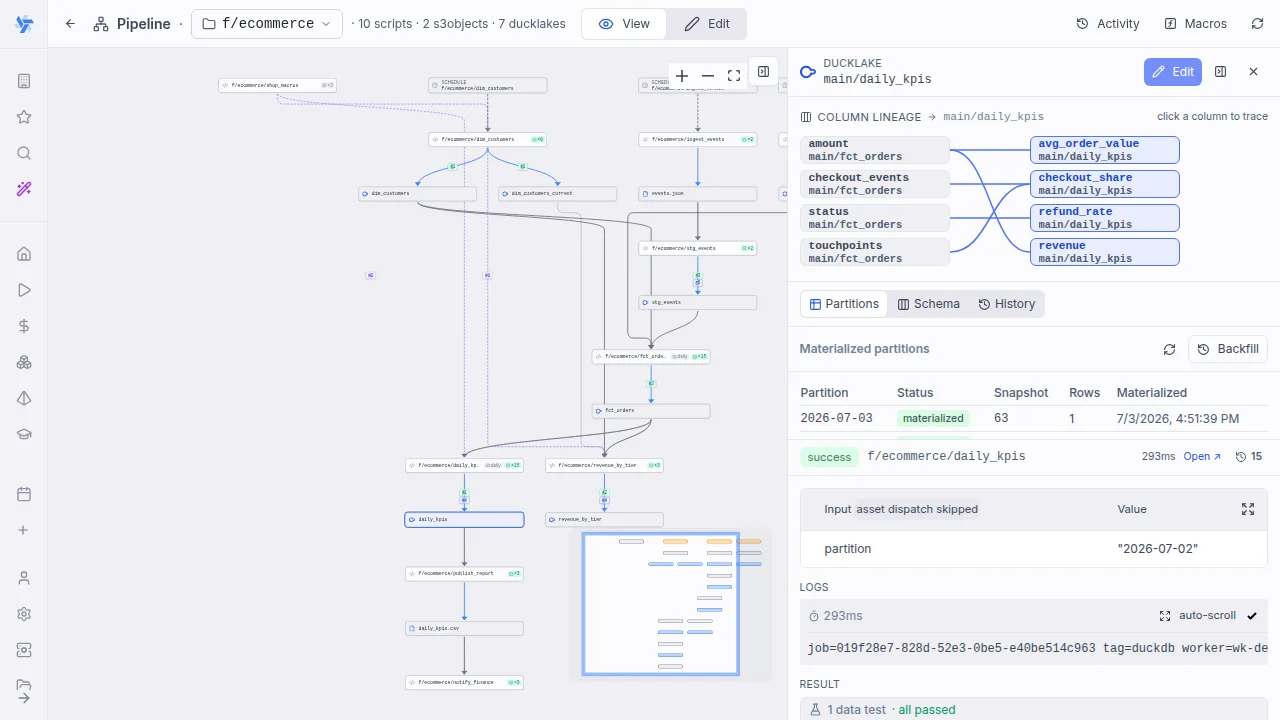
Partitions & backfill
Declare -- partitioned daily (or hourly, weekly, monthly, dynamic) and every run processes exactly one slice. A partition status grid shows what exists, what failed and what is missing, and range backfill re-runs the gaps in one click, each partition an idempotent run.
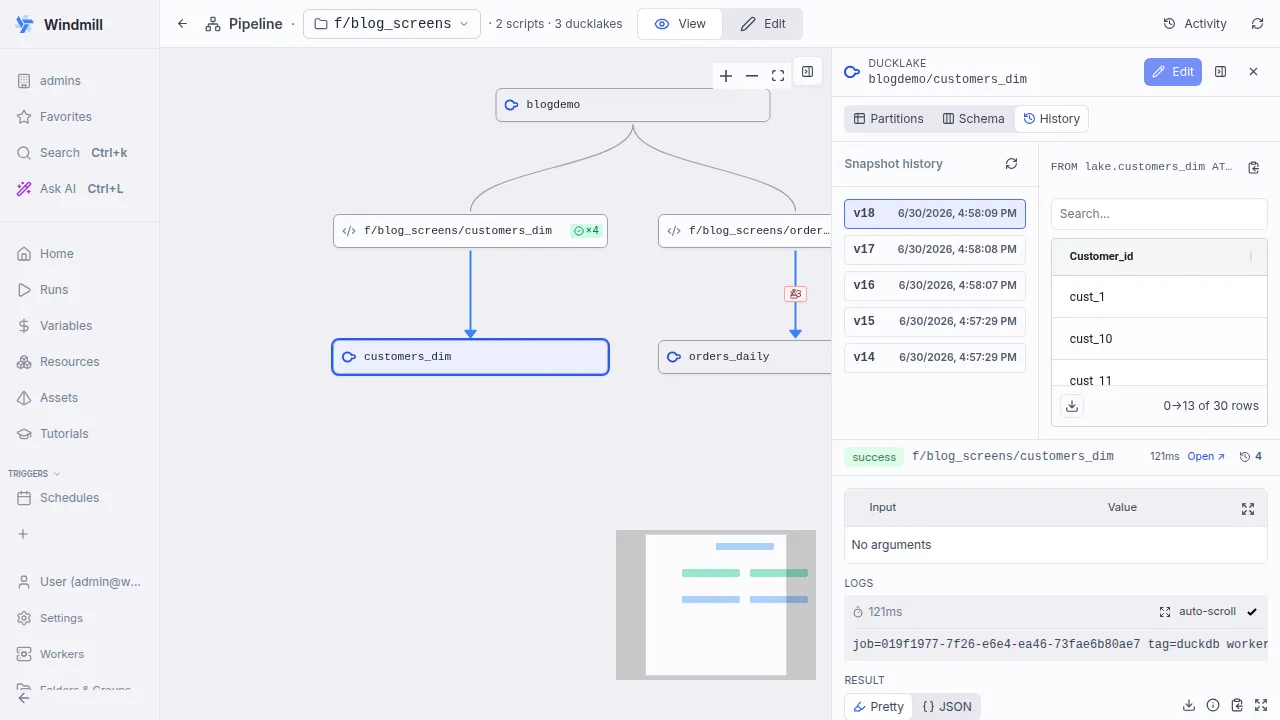
Versioning & time travel
Every managed write is a Ducklake snapshot. Read any table as of a past version with AT (VERSION => n), roll back, or reproduce a past run exactly. Cascaded runs record the snapshot ids of their inputs, so you can always answer which version of each input produced a result.
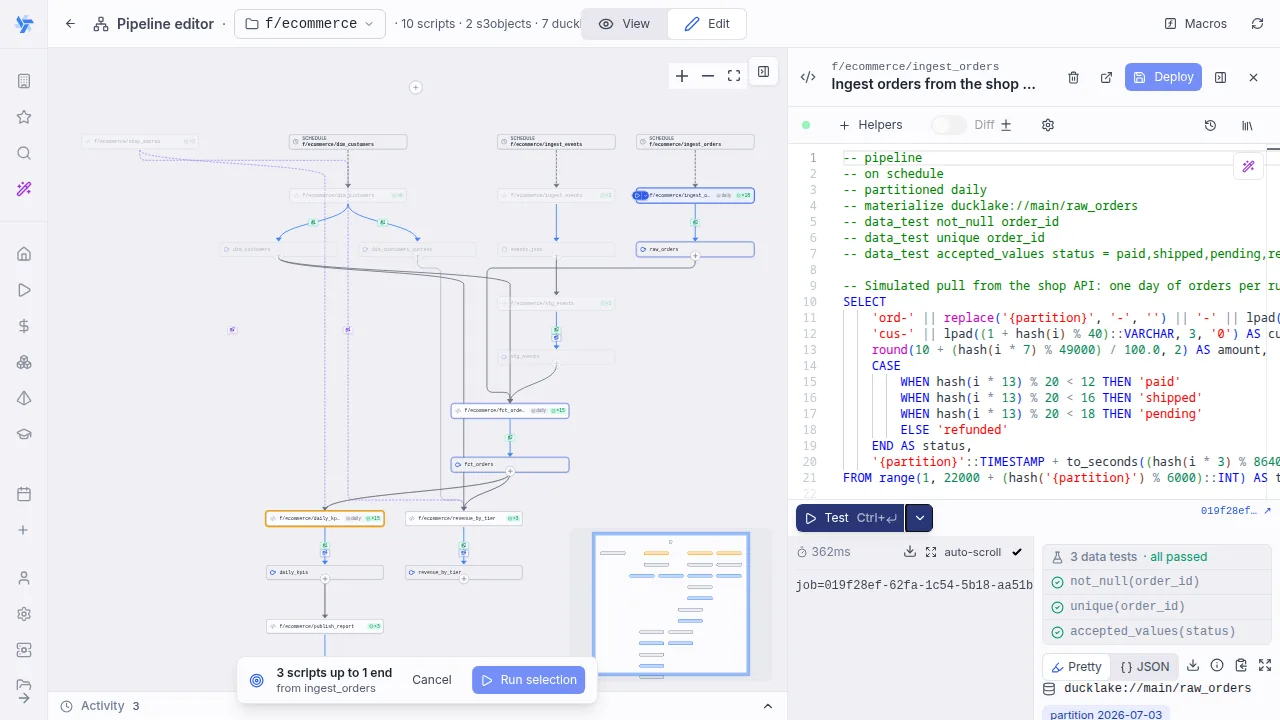
Data tests
unique, not_null, accepted_values, relationships and custom checks run against the freshly materialized slice and fail the run on violation, with a sample of the violating rows in the error. On Enterprise Edition, a failing test rolls back the whole write (write-audit-publish) so readers never see bad data.
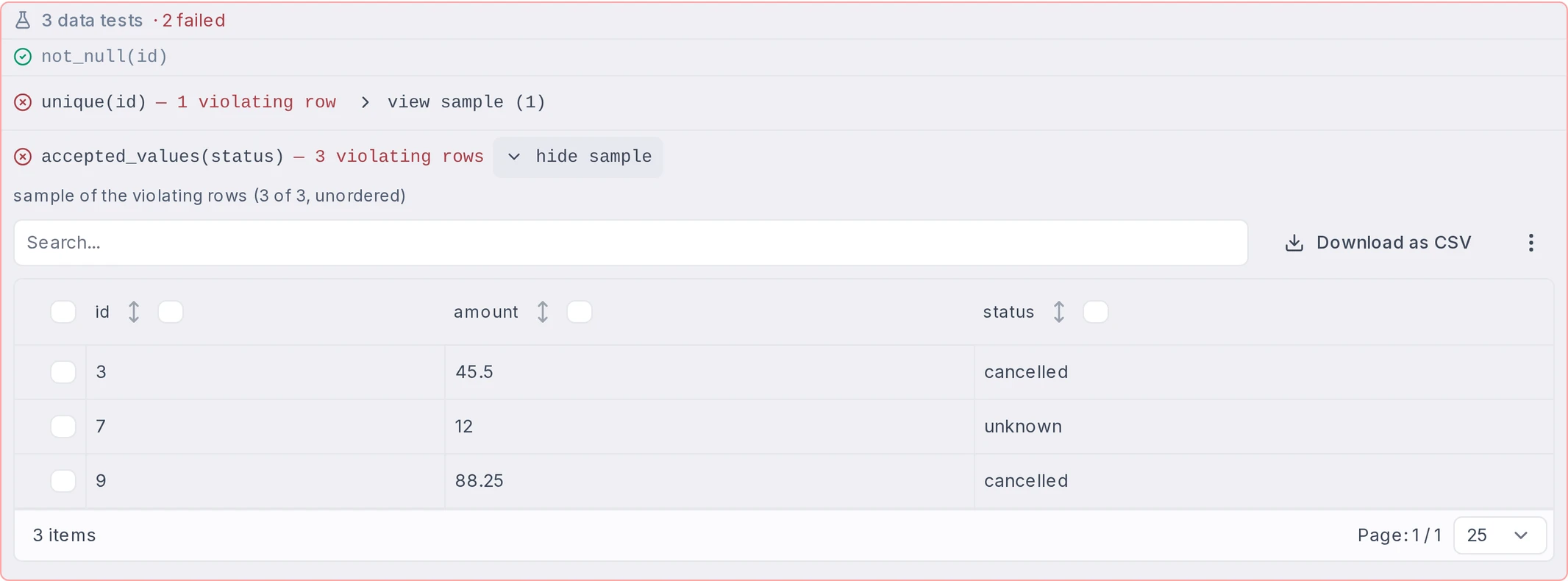
Column lineage & schema contracts
Column-to-column lineage is inferred from the SQL itself: select a column to trace its full upstream and downstream impact across the pipeline. Output schemas are captured on every write, and saving a consumer script checks its column references against them.
Freshness SLOs
Declare -- freshness 2h and every node shows a fresh or stale verdict on the graph. On Enterprise Edition, a watchdog re-runs stale scripts automatically: a backstop that stays out of the way as long as any other trigger keeps the asset current.

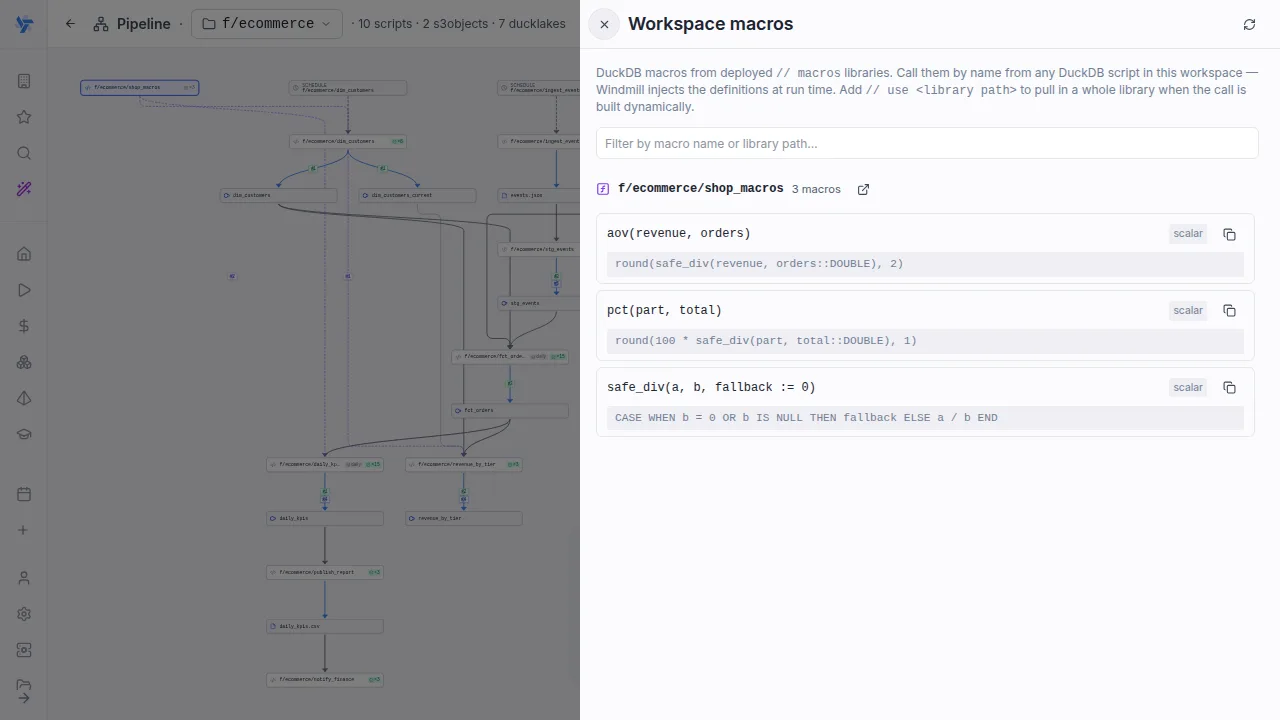
Macro libraries
Share DuckDB logic as engine-native CREATE MACRO libraries: deploy once and every DuckDB script in the workspace can call them, no import needed. Real functions with signatures and autocomplete, not templated text.
Selective execution
Run a single step, a step and everything downstream, or a bounded slice: pick an entry point and the nodes to stop at, and Windmill runs exactly the path between them. The same bounds work from the CLI with wmill pipeline run --from --to.
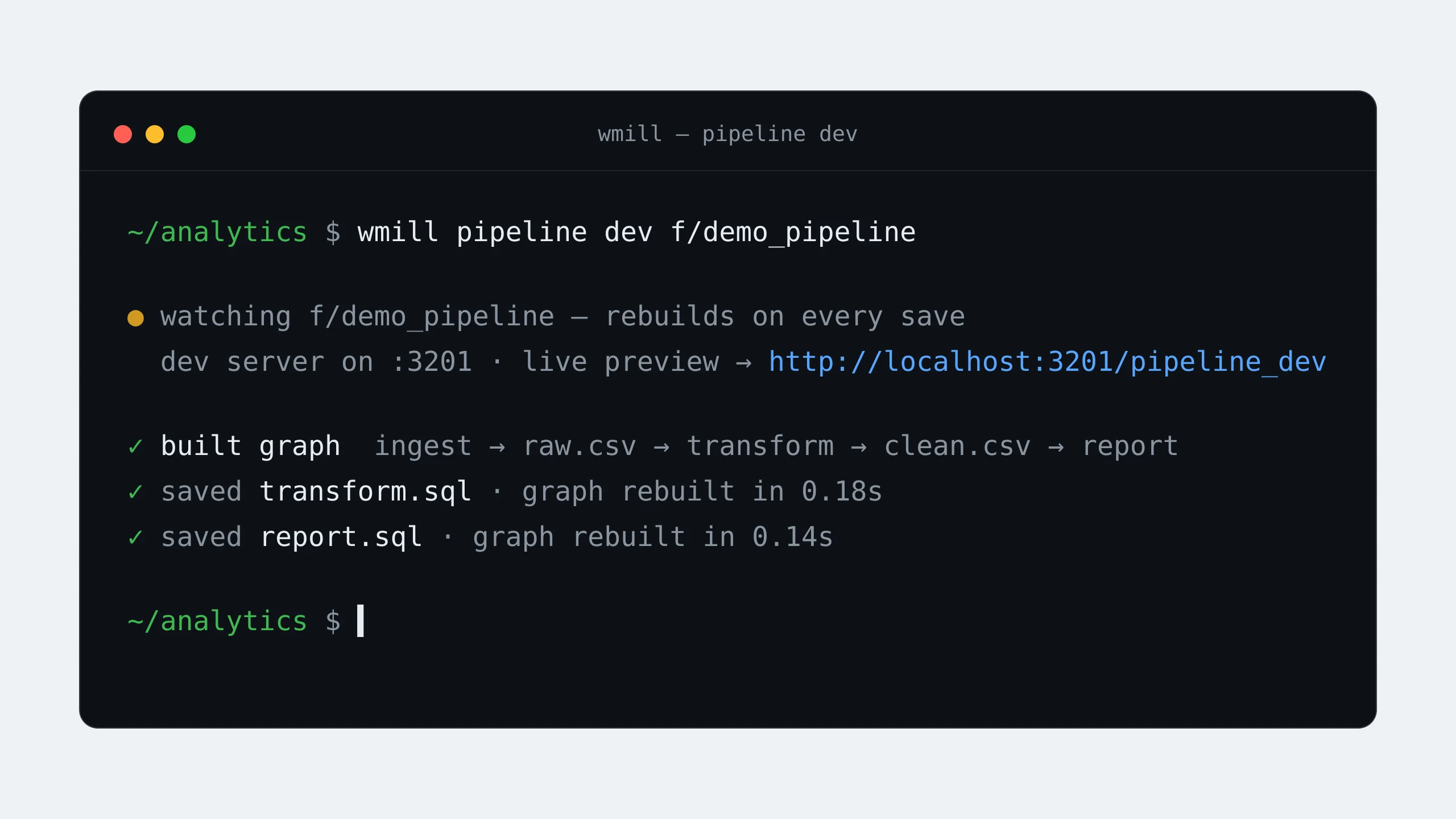
Local dev, forks & AI
Develop pipelines from your own machine: wmill pipeline dev watches your working tree and live-previews the graph in the browser as you edit, and wmill pipeline run --local runs it without deploying. The AI chat builds and edits pipelines directly, and workspace forks get an isolated Ducklake data environment, so dev runs write to dev tables and read missing ones from production through defer views.
Not just an orchestrator, a full runtime
dbt and Dagster popularized the asset-and-lineage model, but each owns only part of the job: dbt transforms SQL in a warehouse you provide, Dagster orchestrates assets whose compute lives elsewhere. Windmill runs the transforms itself on DuckDB, owns the storage in Ducklake, and schedules and triggers everything on your own workers.
| Windmill |  dbt dbt |  Dagster Dagster | |
|---|---|---|---|
| What it is | Runtime + orchestrator + storage | SQL transform framework | Asset orchestrator |
| Runs the transforms | Yes, DuckDB in-platform | No, your warehouse does | No, calls dbt or your code |
| Compute | Your workers, local DuckDB | Your warehouse | External (warehouse, K8s, Spark) |
| Storage & versioning | Managed Ducklake, time-travel | The warehouse | Bring your own (IO managers) |
| Scheduling & triggers | Built-in (cron, webhooks, CDC) | External scheduler needed | Built-in |
| Languages | SQL, Python, TypeScript, Go, Bash | SQL (+ limited Python) | Python |
| Beyond data pipelines | APIs, apps, AI agents, workflows | No | No |
Pipelines are in alpha. Windmill also orchestrates dbt models and warehouse queries if you already run them. See the full comparison, including where dbt and Dagster still win today.
Production-grade orchestration around every pipeline
Write each step in Python, TypeScript, SQL, Go, Bash or any supported language, connect to your data sources with typed resources, and deploy with built-in scheduling, retries, error handling and observability.
Steps as code
Write each pipeline step in the language that fits best. Python, TypeScript, SQL, Go, Bash, Rust, PHP and 20+ more. Mix and match freely within a single pipeline.
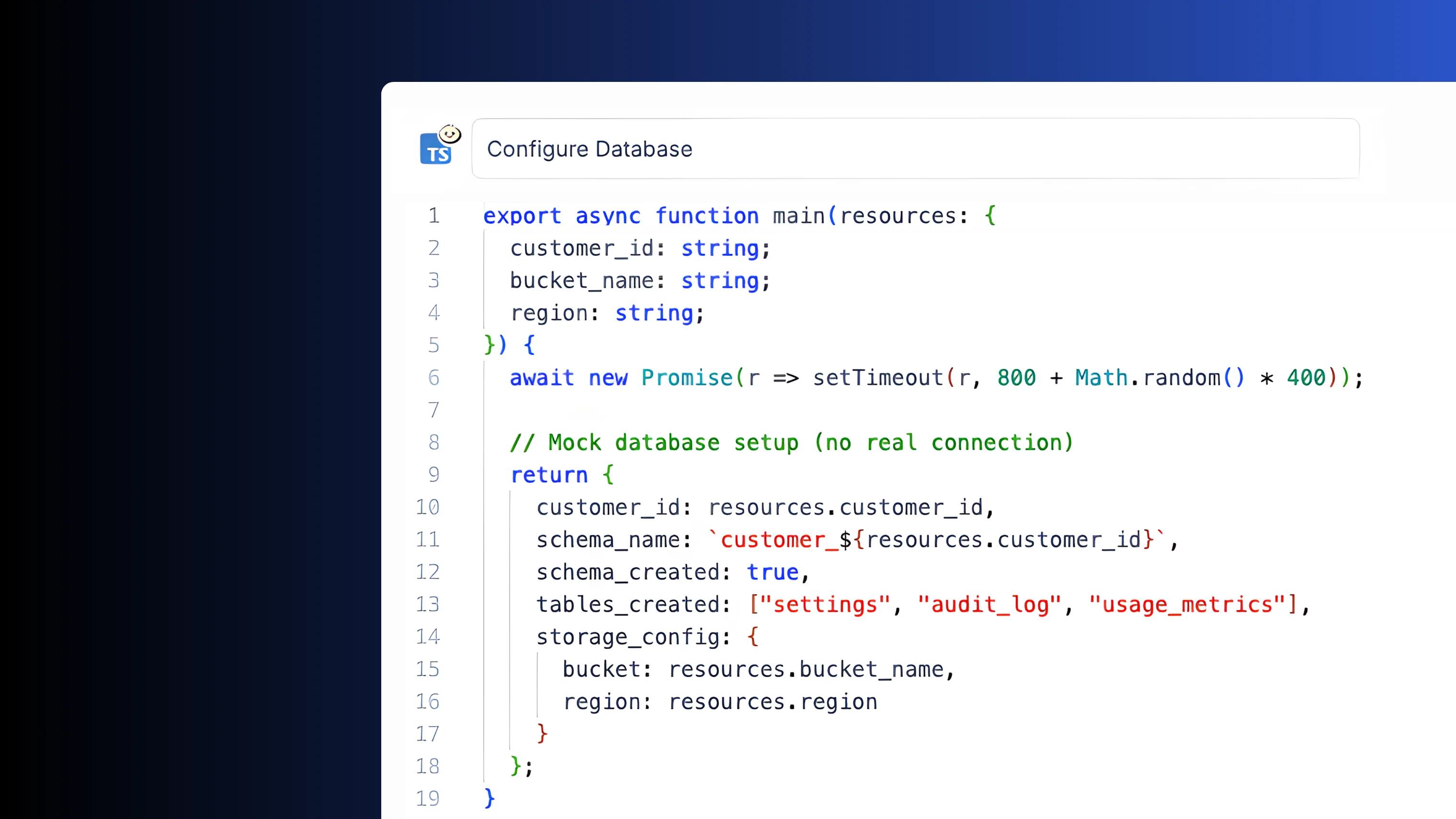
Connect to any service
Connect to databases, APIs and third-party services using typed resources. Credentials are stored centrally and injected at runtime. Share connections across scripts and flows without duplicating secrets.
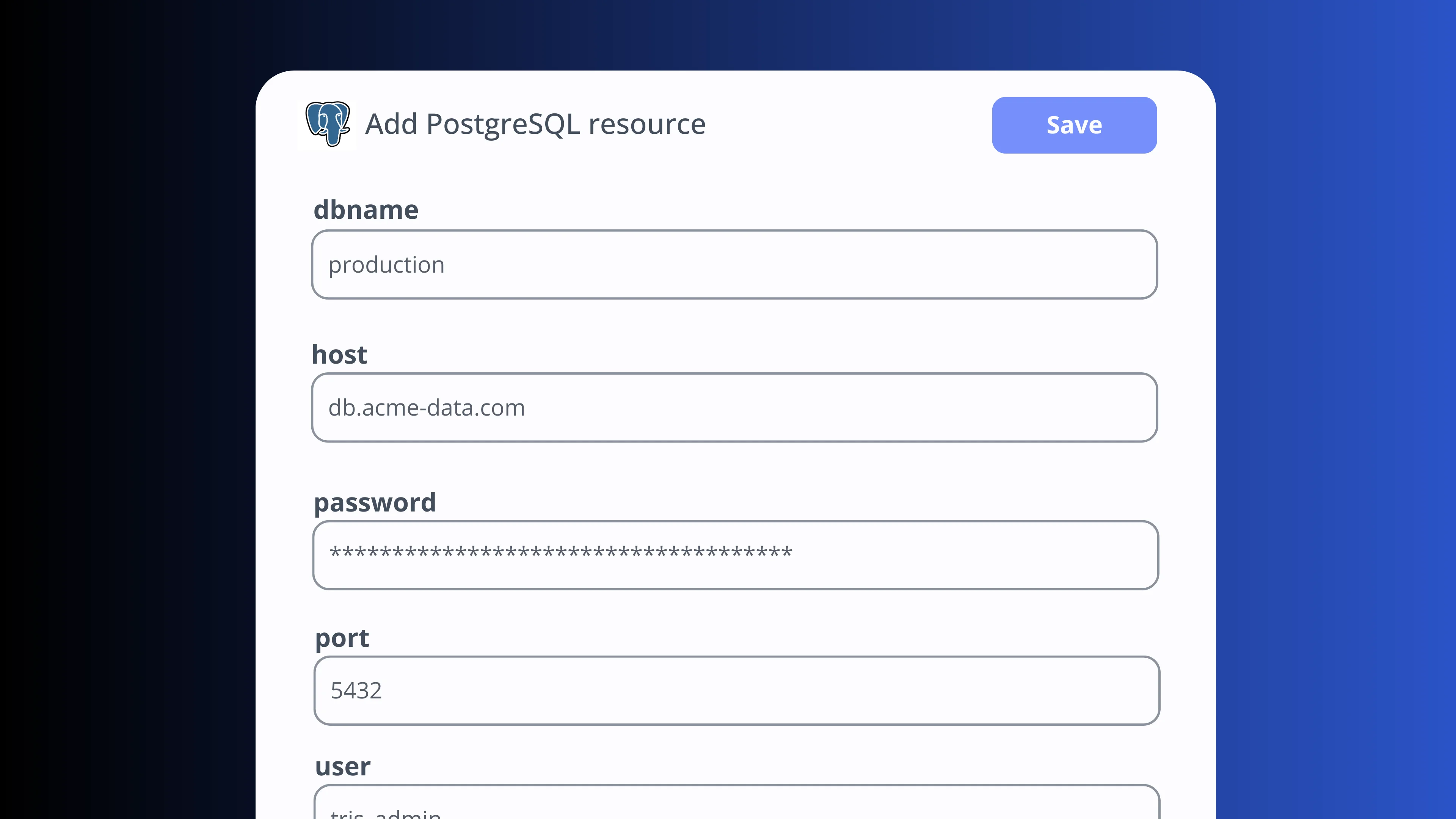
Retries & error handlers
Each step can have its own error handling strategy and configurable retries with exponential backoff. Run a custom script on failure (send a Slack alert, create a ticket), stop the pipeline early or mark non-critical steps to continue on error.
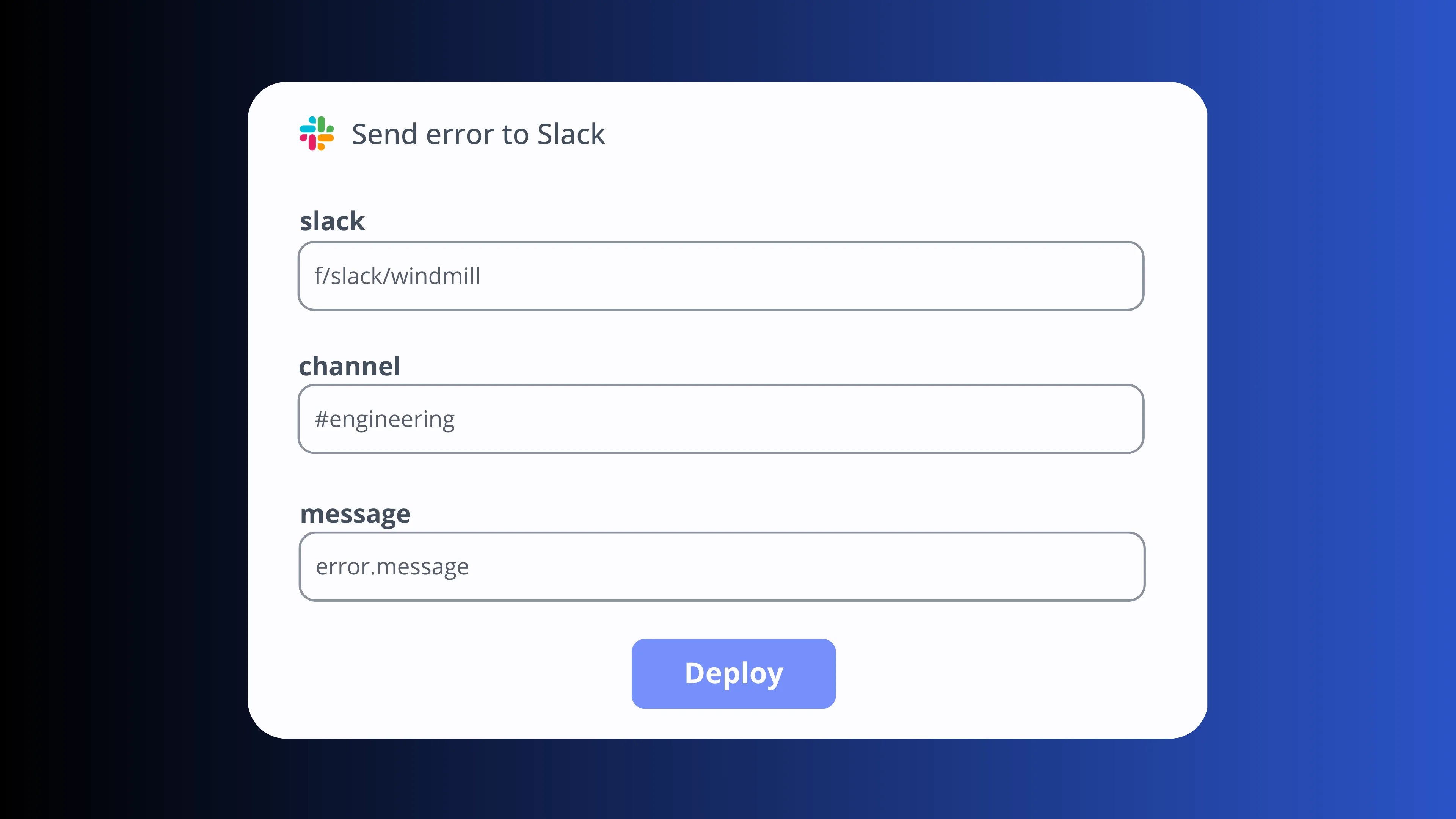
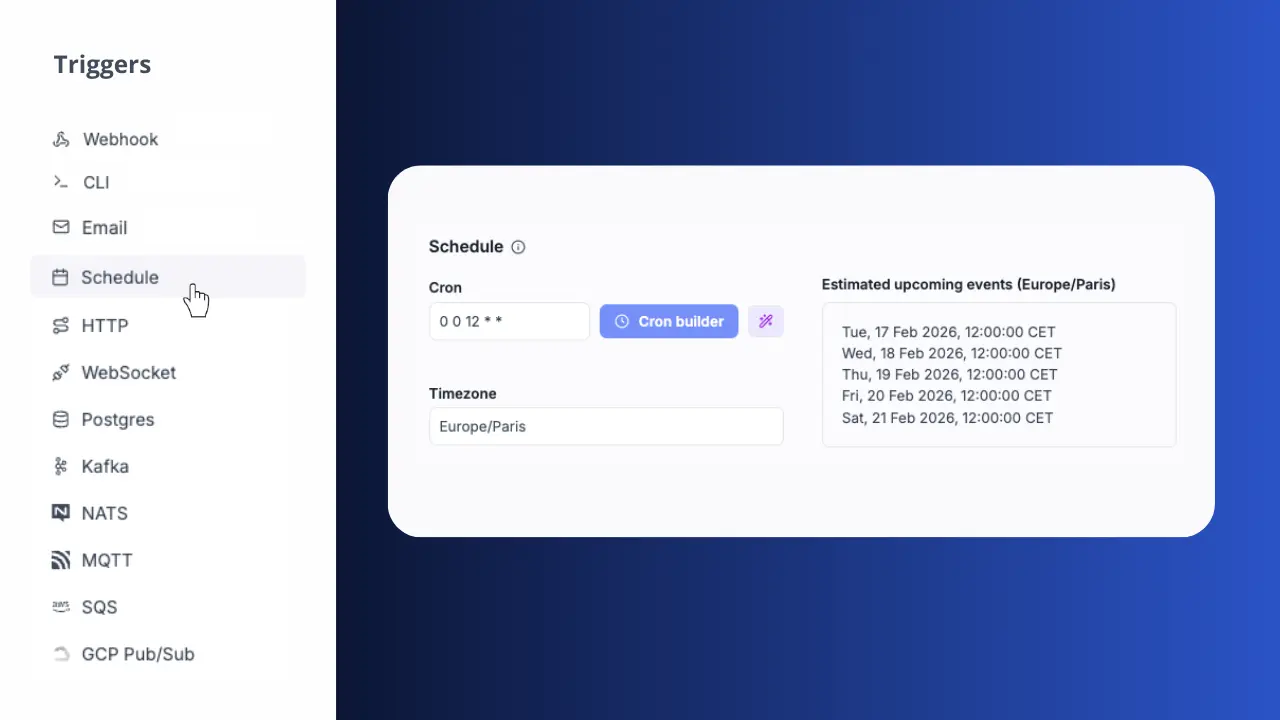
Trigger from anywhere
Start pipelines from cron schedules, webhooks, Postgres CDC, Kafka, SQS, or manually from the UI. Combine multiple trigger types on the same pipeline.
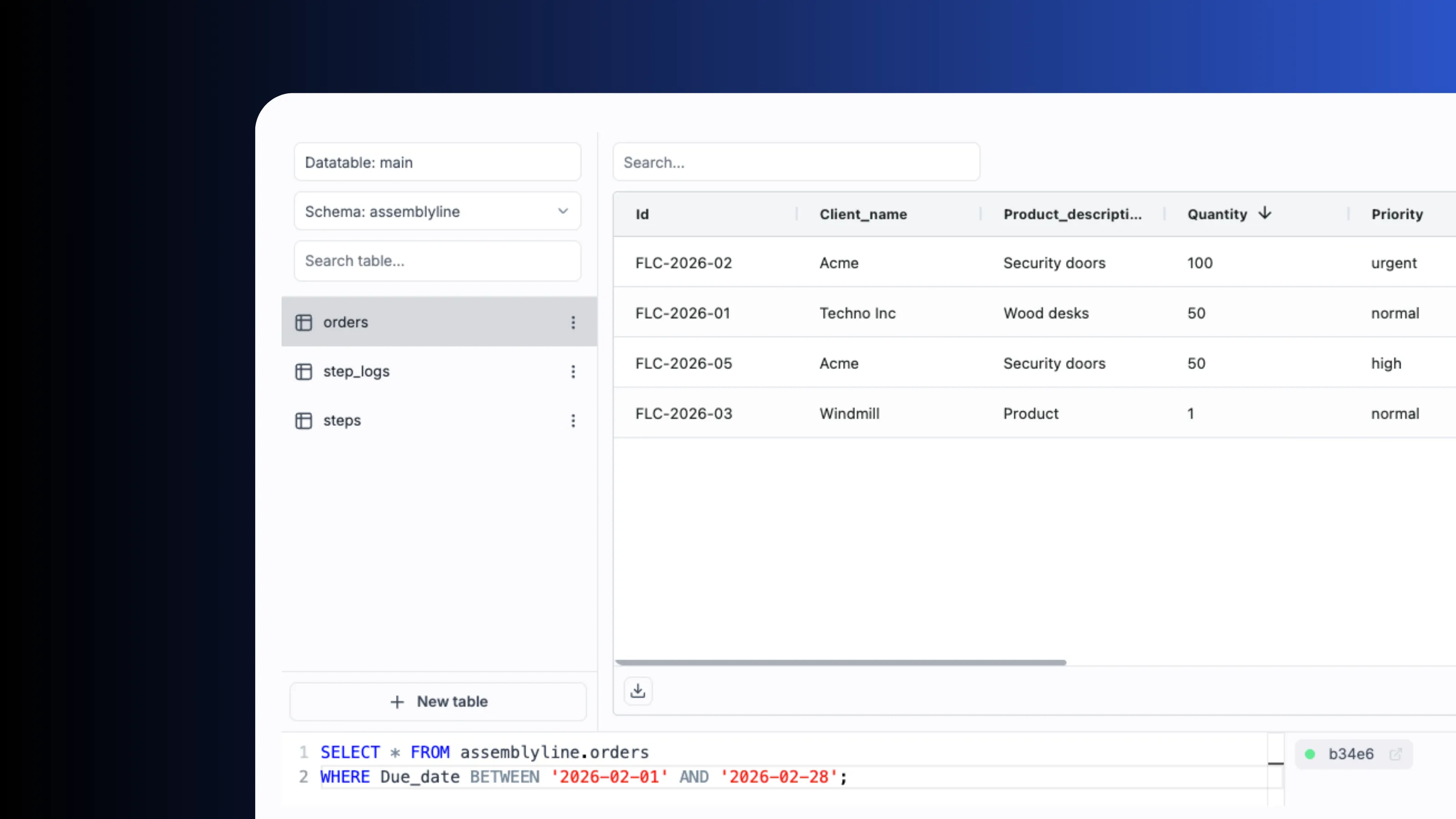
Data tables
Built-in relational storage with zero setup via data tables. Query from Python, TypeScript, SQL or DuckDB. Credentials are managed internally and never exposed.
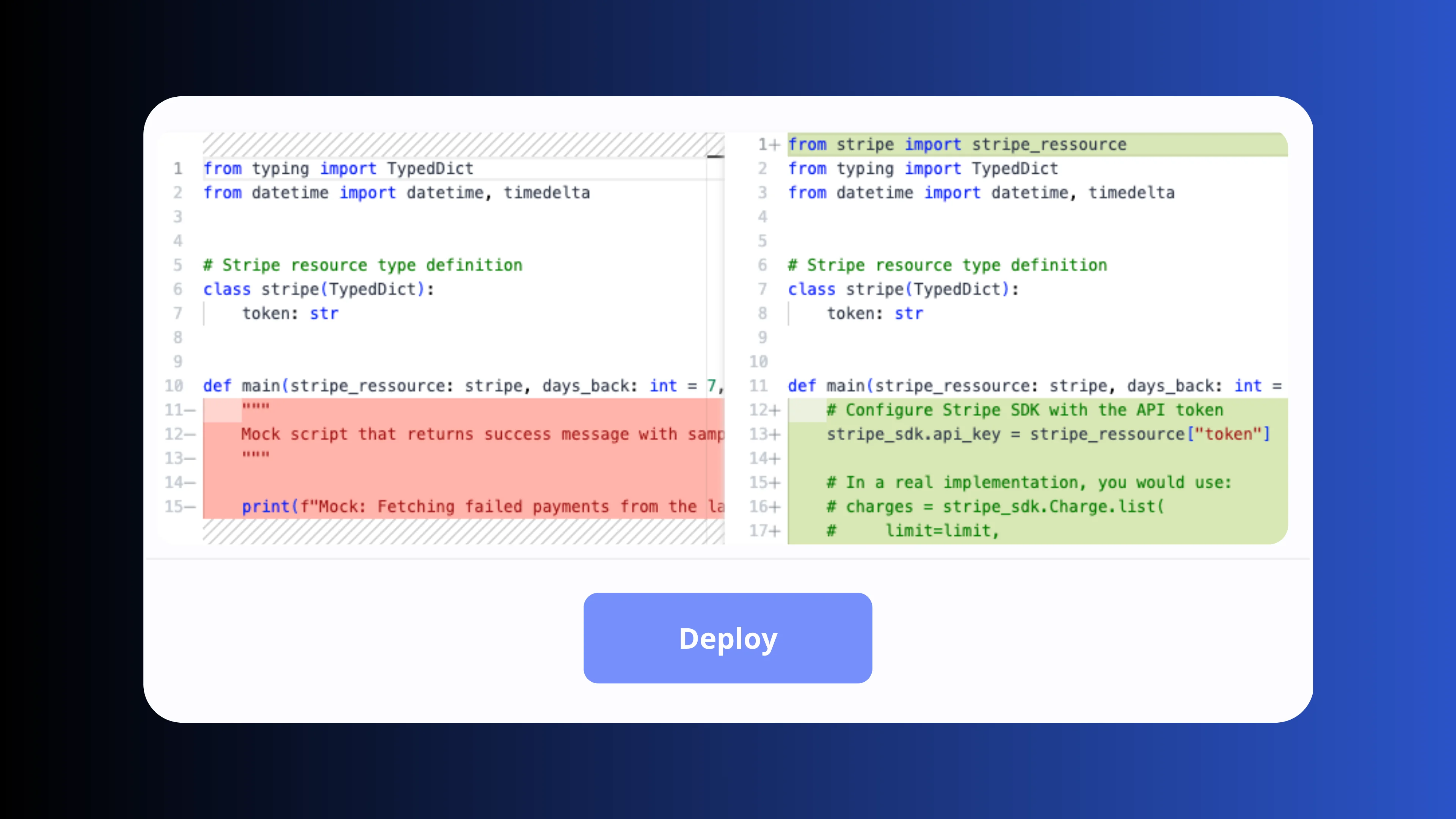
Deploy & version control
Promote pipelines from draft to production in one click with full deployment history and instant rollbacks. Sync your workspace with GitHub or GitLab, use your existing code review workflows and deploy via the UI, the CLI or CI/CD pipelines.
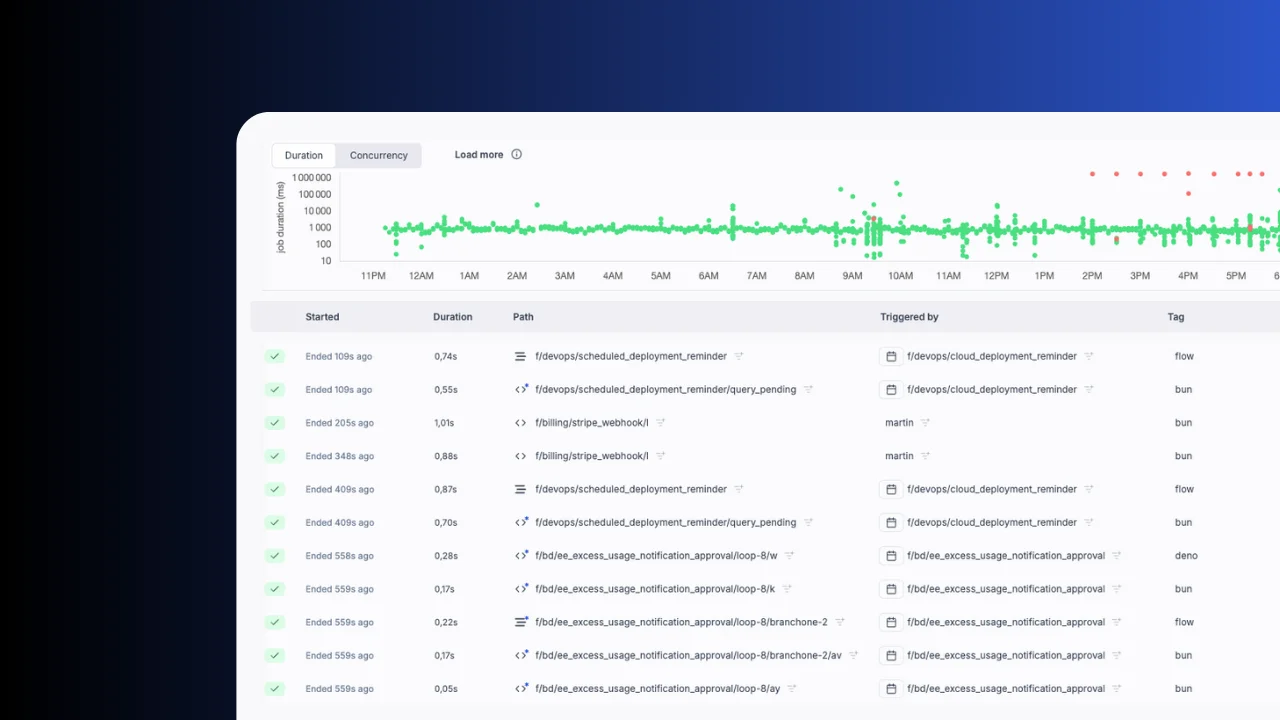
Full observability
Every pipeline run is logged with inputs, outputs, duration and status. Filter by success or failure, inspect logs and re-run with one click. Track resource usage, monitor worker groups and set up alerts for failures.
Zero-config access to your data sources
DuckDB, Ducklake and object storage connect with zero setup, and 50+ more databases and SaaS sources link once and are reused across every step. Credentials and connection strings are handled for you, so you just write your query.
DuckDB
Query S3 files with SQL. DuckDB scripts auto-connect to your workspace storage. No credentials to manage, no connection strings to configure.
Ducklake
Store massive datasets in S3 and query them with SQL. Full data lake with catalog support, versioning, ACID transactions, scheduled maintenance and managed materialization from pipelines.
Workspace S3
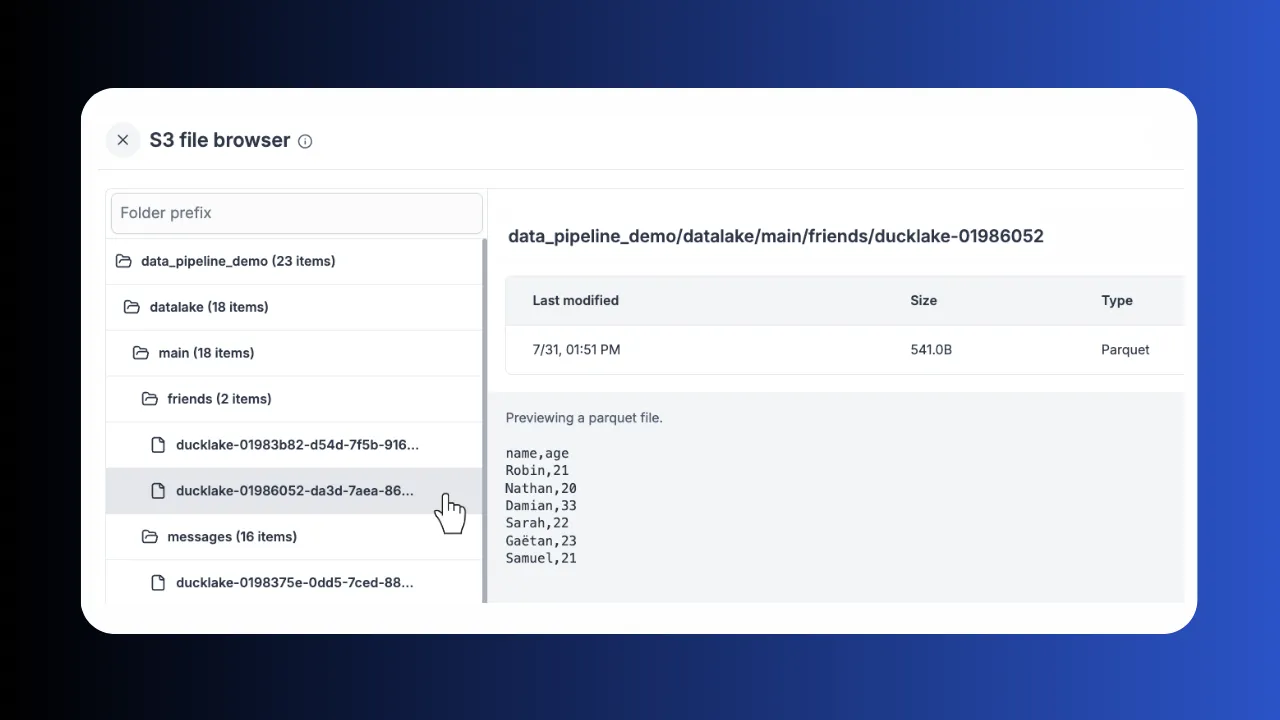
Link your workspace to S3, Azure Blob, GCS, R2 or MinIO. Browse and preview Parquet, CSV and JSON directly from the UI.
Polars
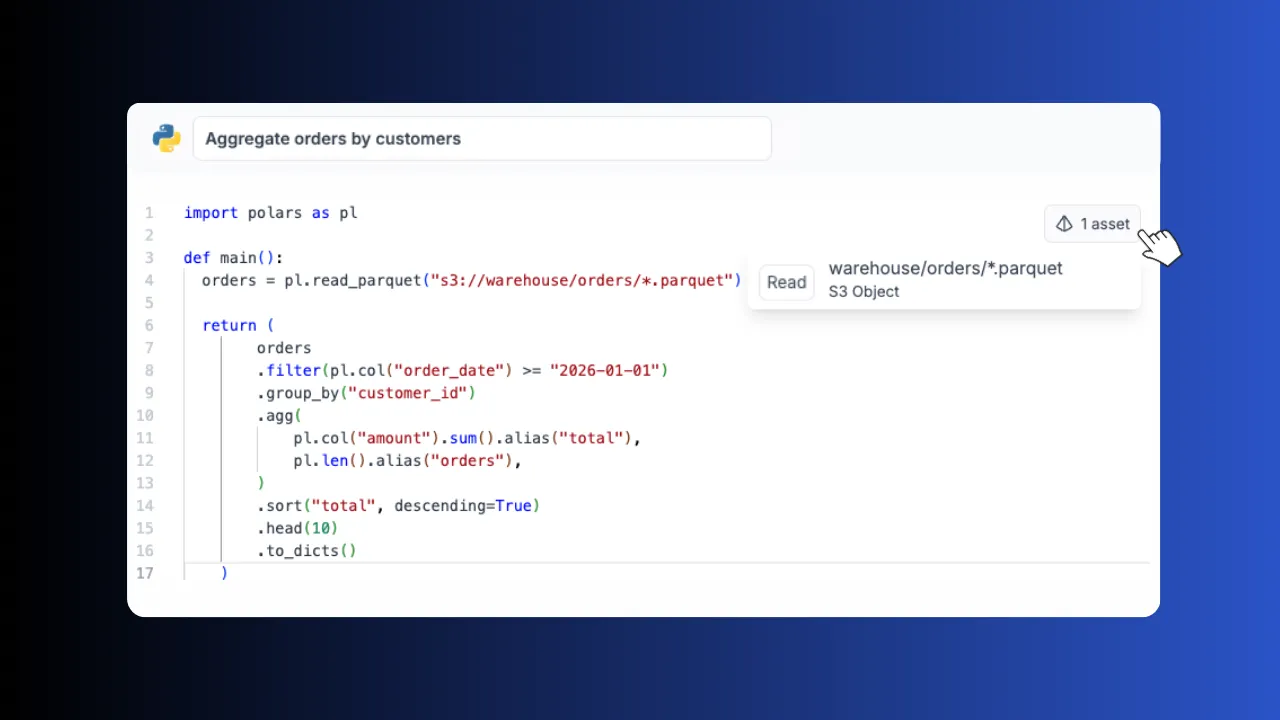
Process data as DataFrames in Python, reading and writing the same auto-connected workspace storage as DuckDB. Every read_parquet on S3 is detected as an asset, so lineage comes for free. The fast path for the non-SQL transforms in a pipeline.
Snowflake & BigQuery
Query Snowflake, BigQuery, Redshift and other warehouses from a step with a typed resource. Windmill orchestrates the query and pulls the results into your pipeline. One difference to keep in mind: the compute runs in the warehouse, not on your workers like DuckDB and Polars, so you can mix warehouse steps and local DuckDB steps in the same pipeline and pay warehouse compute only where you need it.
Challenging the status quo of data warehouses
Stop paying per-query. Run DuckDB and Ducklake locally on your workers.
| Windmill + DuckDB | Snowflake / BigQuery | |
|---|---|---|
| Compute | Local on your workers | Remote warehouse |
| Cost model | Flat, pay for infra only | Per-query pricing |
| Data storage | Your S3 bucket, open formats | Vendor-managed, proprietary |
| Vendor lock-in | No | Yes |
| Orchestration | Built-in (flows, retries, schedules) | Separate tool needed |
| Setup | Zero config, auto-connected | Credentials, drivers, networking |
| Data egress fees | No | Yes |
Windmill also orchestrates Snowflake, BigQuery and other warehouses. You can mix local DuckDB steps with remote warehouse queries in the same pipeline.
Production-grade performance that replaces Spark
Polars and DuckDB process data on a single node far faster than distributed frameworks for the vast majority of ETL workloads.
TPC-H-derived benchmark (unaudited), 9 queries run sequentially, median of warm runs. Re-run July 2026 on a single AMD Ryzen 9 9900X (12 cores / 24 threads, 60 GB), reading Parquet from S3 (MinIO on localhost). DuckDB queries the Parquet directly; Polars "eager" runs out of memory past 10G (0 in the chart). Not comparable to the original 2023 AWS run. Method & raw data.
More you can build on Windmill
Data pipelines are just one use case. The same platform powers internal tools, AI agents, workflows and triggers.
Write scripts in TypeScript, Python, Go, Bash, SQL and trigger them from webhooks, schedules, queues or the auto-generated UI.
Build production-grade internal apps with backend scripts, data tables and React, Vue or Svelte frontends.
Build AI agents with tool-calling, DAG orchestration, sandboxes and direct access to your scripts and resources.
Chain scripts into flows with approval steps, parallel branches, loops and conditional logic.
Run cron jobs with a visual builder, execution history, error handlers, recovery handlers and alerting.
Run PowerShell, MSSQL with Kerberos and C# natively on domain-joined Windows servers, no Docker required.
Frequently asked questions
Build your internal platform on Windmill
Scripts, flows, apps, and infrastructure in one place.