9 posts tagged with "Scripts"
View All TagsBash scripts starting with a #ssh <resource_path> directive now run on the remote host described by the referenced ssh_target resource, for jump/utility nodes where no worker can be placed. Full parity with local bash jobs - typed positional args, structured result, live streamed logs, cancellation and remote exit-code propagation. Enterprise feature, off by default (ssh_execution_enabled instance setting). Agent workers remain the recommended way to run code in isolated environments.
New features
- Add `#ssh <resource_path>` as the first comment line of a bash script to run it on the remote host of an `ssh_target` resource.
- Full parity with local bash jobs: typed args, result collection (result.json > result.out > last stdout line), live logs, cancellation, remote exit code fails the job.
- Dynamic target with `#ssh $<arg_name>`: the target resource path is supplied as a job argument at call time, resolved through the runner resource permissions.
- Host-key pinning enforced when the resource sets `host_pubkey`; trust-on-first-use only with explicit `accept_unknown_host`.
- Enterprise-gated and off by default: enable the `ssh_execution_enabled` instance setting as a superadmin.
- A userland wrapper (`ssh_exec.sh` / `ssh_exec.py`) with the same SSH mechanics is available without a license in examples/usecase/ssh-execution-wrapper.
Bash scripts can now run any container image with the # sandbox <image> annotation. The image rootfs is pulled with crane and run chrooted inside the job's own nsjail, so it is daemonless, needs no Docker socket or dind sidecar, and is safe to run for untrusted multi-tenant code. Docker scripts are now allowed on Windmill Cloud.
New features
- Run any container image from a bash script with `# sandbox <image>` — the body runs inside the image, sandboxed.
- Daemonless: image rootfs is pulled with crane and run chrooted in the job nsjail, no Docker socket or dind sidecar.
- Inherits the job confinement: no host filesystem, the jail own /proc, unprivileged worker uid, the job network.
- Instance settings for pull policy, per-image and cache size caps, default registry, and private-registry auth.
- Now available on Windmill Cloud since containers run sandboxed.
Write test scripts that run automatically every time the script or flow they cover is deployed.
New features
- Add a "// test: script/path" annotation to turn any script into a test for another script or flow
- Tests run automatically every time the target is deployed
- Results (pass/fail/running) shown on script and flow detail pages
- CI badges and summary on workspace fork comparison page
- Built-in test templates for TypeScript and Python
PowerShell scripts now support private repositories and array/object parameters.
New features
- Support for private repository access
- Parameter support for arrays and objects (PSCustomObject)
Visualize your data flow and automatically track where your assets are used
New features
- Assets are automatically parsed from your code
- Read / Write mode is infered from code context
- Add S3 file assets easily through the editor bar
- Flow graph displays asset nodes as input or output depending on the infered read / write mode
- You can manually select the Read / Write mode for an asset when it is ambiguous in the code
- Passing a resource or an s3 file object as input of a flow will display it as an input asset in the run preview
- Assets page to see where your assets are used
- Explore database / S3 Object Preview button
- Unified URI syntax (res://path/to/res, s3://storage/path/to/file.csv, etc)
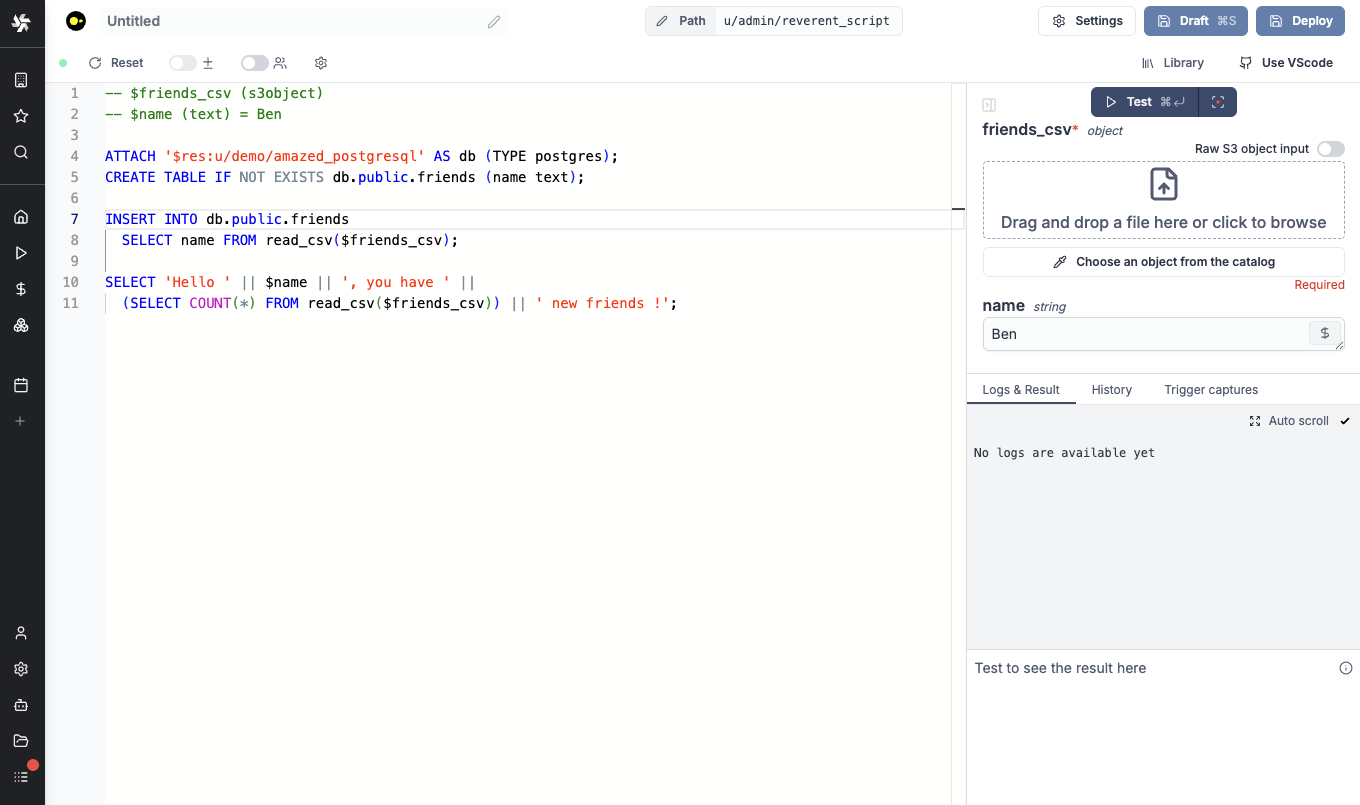
You can run DuckDB scripts in-memory, with access to S3 objects and other database resources. You no longer need a scripting language for your ETL pipelines with DuckDB/Polars, you can do it entirely in SQL
New features
- S3 object integration
- Attach to BigQuery, Postgres and MySQL database resources with all CRUD operations
You can stream the results of a large SQL query to an S3 file in your workspace storages
New features
- Supported formats: json (default), csv, parquet
- Set object key prefix
- Select a secondary storage
It is now possible to use pin annotation to specify dependency you want to be associated with the import. In contrast with "#requirements:" syntax, it is applied import-wise instead of script-wise.
New features
- Python Pins
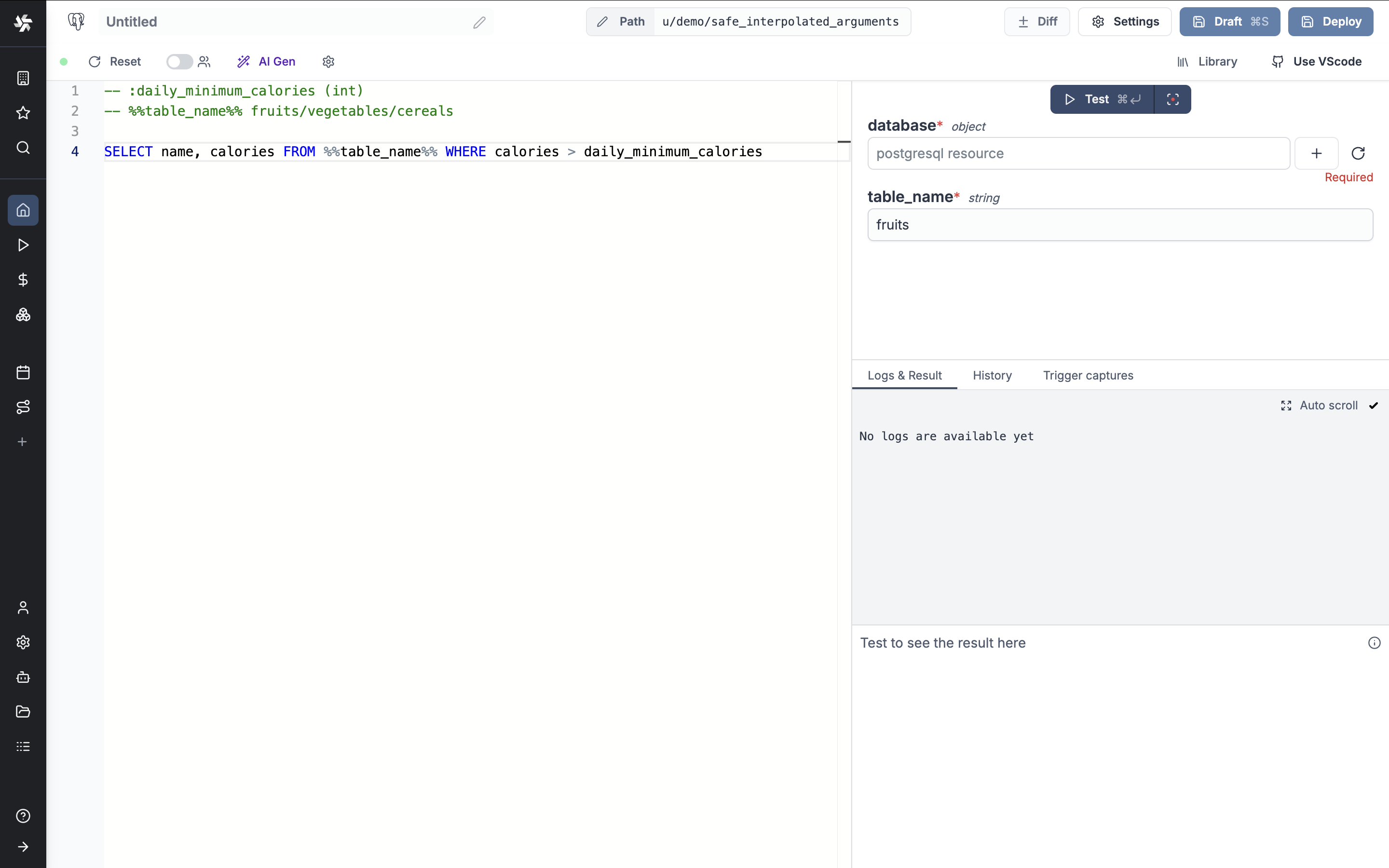
Backend schema validation and safe interpolated arguments for SQL queries.
New features
- Backend schema validation for scripts using the schema_validation annotation.
- Safe interpolated arguments for SQL queries using %%parameter%% syntax.
- Protection against SQL injections with strict validation rules for interpolated parameters.